
Im vorherigen Artikel haben wir über Datenblöcke gesprochen und die zwei verschiedenen Arten von Datenblöcken besprochen, den globalen Datenblock und die Dateninstanzen von Funktionsblöcken FBs.
In diesem Artikel werden wir besprechen, was mit optimiertem Datenblockzugriff und standardmäßigem Datenblockzugriff im Siemens Tia Portal gemeint ist.
Inhalt:
- Was sind optimierte und standardmäßige Datenblöcke?
- Einfaches Programmbeispiel.
- Was sind Standard-DBs? Was ist der Offset?
- Was sind optimierte DBs?
- Vorteile der Verwendung optimierter DBs.
- Schlussfolgerungen.
Was ist optimierter und standardmäßiger Datenblockzugriff?
Erstens sind dies keine neuen Arten von Datenblöcken; wir sagten, wir haben nur zwei verschiedene Arten, den globalen DB und den Instanz-DB. Optimierter Datenblockzugriff ist eine Funktion für den Datenblock. Sie können diese Funktion in den Eigenschaften des von Ihnen erstellten Datenblocks aktivieren oder deaktivieren.
Die optimierte Datenblockfunktion ist nur für S7-1200- und S7-1500-SPS verfügbar, nicht für S7-300 oder S7-400.
Die Standardeinstellung für Datenblöcke bei der Arbeit mit S7-1200- oder S7-1500-SPS ist, dass sie optimiert sind. Wenn Sie einen Standarddatenblock möchten, müssen Sie diesen selbst festlegen.
Was sind also optimierte und Standardblöcke? Um den Unterschied zu verstehen, erstellen wir ein einfaches Programm und versuchen zu zeigen, wie sich ein optimierter Block von einem Standardblock unterscheidet.
Einfaches Programmbeispiel:
In diesem Beispiel erstellen wir keine SPS-Logik und codieren keine Anweisungen. Wir erstellen nur zwei globale Datenblöcke. DB1 wird OptimizedDB und DB2 StandardDB genannt.
In beiden Datenblöcken deklarieren wir jeweils vier Variablen der Datentypen Bool, Int, Real und Word. Siehe Bild 1.

Bild 1 – Zwei globale DBs erstellen
Als Erstes werden Sie feststellen, dass beide Datenblöcke genau gleich sind. Das liegt daran, dass die Standardeinstellung beim Erstellen eines Datenblocks, wie gesagt, die Optimierung ist. Wir müssen also die Einstellung von DB2 ändern, um daraus einen Standardblock zu machen und zu sehen, ob sich etwas ändert.
Wir tun das über die Eigenschaften dieses DB2. Sie greifen auf die Eigenschaften von DB2 zu, indem Sie mit der rechten Maustaste auf den Datenblock klicken und auf Eigenschaften drücken. Siehe Bild 2.

Bild 2 – DB2 auf Standardblockzugriff ändern
Sobald Sie die in Bild 2 gezeigten optimierten Blockzugriffsattribute abwählen und auf OK drücken, wird eine Warnmeldung angezeigt, siehe Bild 3.

Bild 3 – Popup „Blockzugriff ändern“
Sobald Sie auf OK drücken, wird Ihr DB2 auf Standardblockzugriff umgestellt. Siehe Bild 4. Um zu sehen, welchen Unterschied das gemacht hat.

Bild 4 – DB2 ist jetzt ein Standardblock
Was wir direkt sehen können, ist, dass DB1 und DB2 nicht mehr dasselbe sind. Die in DB2 dargestellte Standardblockzugriffsoption hat eine zusätzliche Spalte namens Offset.
Vor jeder Variable im Offset-Feld steht ein … geschrieben, dies ändert sich, sobald Sie Ihr Programm kompilieren.
Lassen Sie uns kompilieren und sehen, was passiert, siehe Bild 5.

Bild 5 – Kompilieren Sie Ihr Programm, um den Offset neu zu laden
Jetzt wird der Offset mit 0,0, 2,0, 4,0 bzw. 8,0 ausgefüllt, wie Sie sehen können.
Also, was ist dieser Offset? Was bedeutet er? Darauf kommen wir später zurück, aber jetzt erstellen wir einen weiteren STANDARD-Block und deklarieren dieselben 4 Variablen, aber dieses Mal ändern wir die Reihenfolge der variablen Datentypen, siehe Bild 6.

Bild 6 – Einen weiteren Standardblock DB3 erstellen
Sie sehen im letzten Bild, dass der Offset von DB2 und DB3 unterschiedlich ist. Warum sind die Offsetwerte unterschiedlich, als wir die Reihenfolge der Datentypen geändert haben? Es sind dieselben Datentypen, aber in anderer Reihenfolge.
Erstellen wir einen weiteren Standard-DB und deklarieren dieselben 4 Variablen, aber wieder in anderer Reihenfolge. Kompilieren Sie Ihren SPS-Code und vergleichen Sie nun den Offset der 3 DBs. Siehe Bild 7.

Bild 7 – Drei verschiedene DBs mit drei verschiedenen Offsets
Das Gleiche passierte erneut.
Was sind Standard-DBs? Was ist der Offset?
Datenblöcke mit Standardzugriff haben eine feste Struktur. Wenn Sie eine Variable in einem Standard-DB deklarieren, wird dieser Variable eine feste Adresse in diesem DB zugewiesen.
Die Adresse dieser Variable wird in der Spalte „Offset“ angezeigt. Was wir also in den vorherigen Bildern im Offset gesehen haben, war die jeder Variable zugewiesene Adresse.
Da die Struktur von Standard-DBs fest ist, können Sie nur in DBs mit fester Speicherkapazität arbeiten, d. h. einem 16-Bit-Bereich oder 2 Bytes. Dies ist der Grund für die unterschiedliche Adressierung derselben Variablen, wenn wir die Deklarationsreihenfolge geändert haben. Weitere Erklärungen finden Sie in Bild 8.
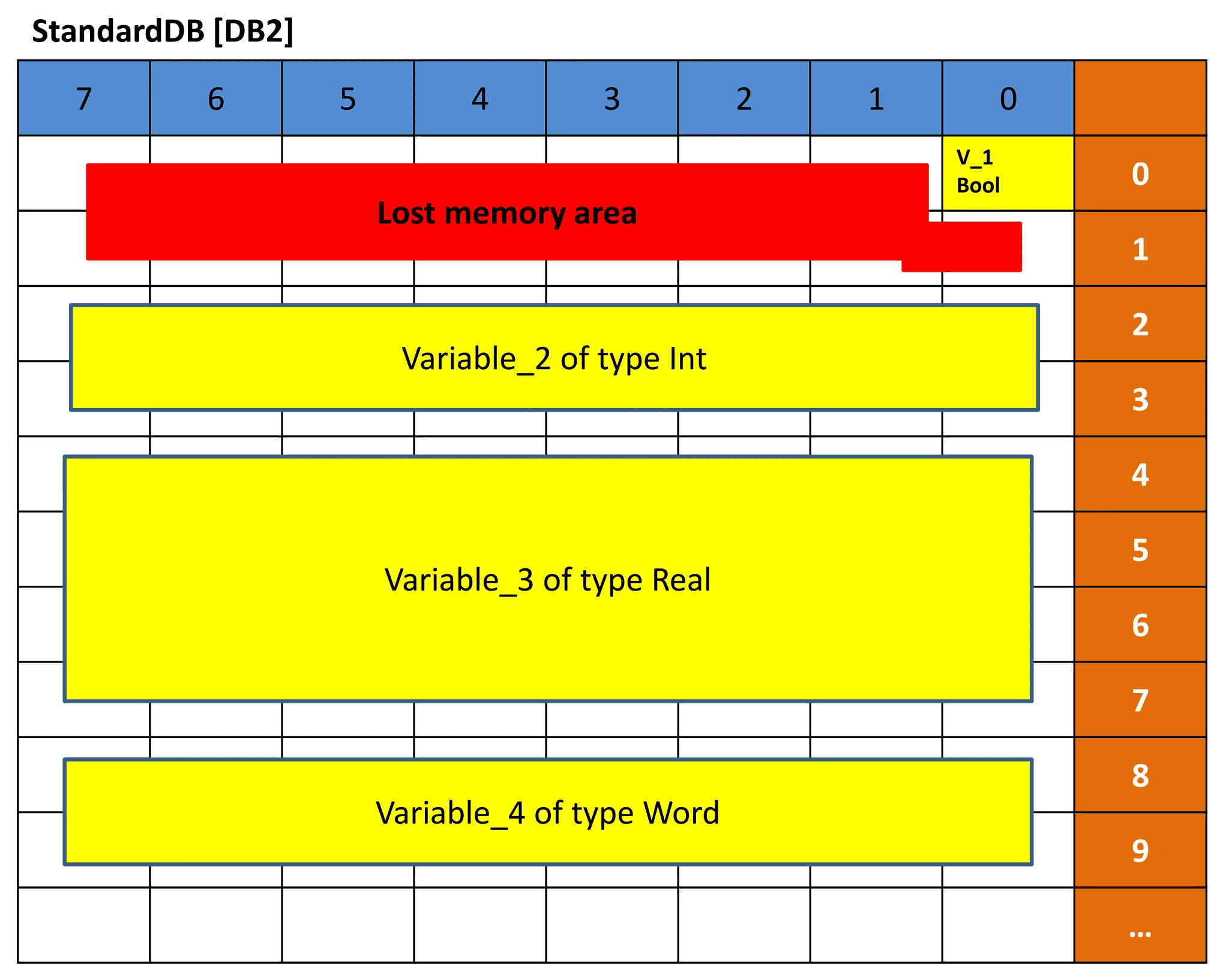
Bild 8 – Einfache Darstellung von DB2
Bild 8 zeigt eine einfache Darstellung des Standarddatenblocks DB2. Wie bereits erwähnt, hat ein Standard-DB feste Speicherblöcke von 16 Bit. Wenn wir also Variable_1 als Datentyp BOOL deklarieren, belegt diese Variable die gesamten 16 Bit, obwohl sie nur 1-Bit-Speicher benötigt. Deshalb sehen Sie den Rest des Bereichs rot markiert, da er nicht verwendet wird, aber nicht mehr verwendet werden kann. Es handelt sich also um verlorenen Speicher.
Bei Variable_2 benötigt der Datentyp INT 16 Bit, sodass 2 ganze Bytes verwendet werden. Dasselbe gilt für Variable_4, die vom Datentyp WORD ist.
Bei Variable_3 belegten wir 4 Bytes, da sie vom Datentyp REAL ist. Deshalb beträgt der Offset für DB2 jeweils 0,0, 2,0, 4,0 und 8,0.
Dasselbe Konzept wird für DB3 und DB4 ausgeführt. Da jedoch die Datentypreihenfolge der Variablen unterschiedlich ist, ist die Speicherdarstellung unterschiedlich und daher auch der Offset unterschiedlich. Sehen Sie sich die Bilder 9 und 10 für DB3 und DB4 an. Versuchen Sie, die Darstellung anhand der vorherigen Erklärung zu verstehen.
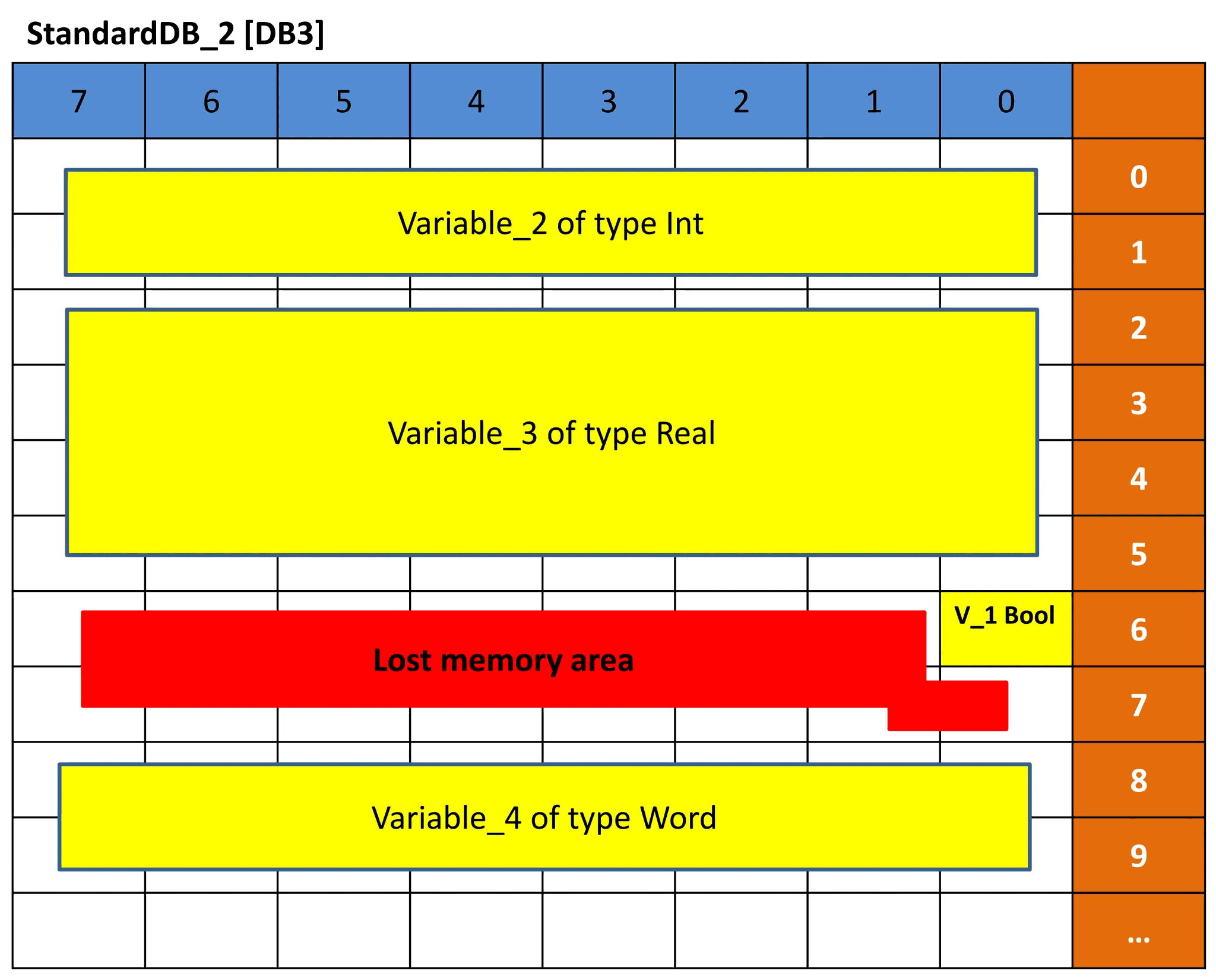
Bild 9 – Speicherdarstellung von DB3
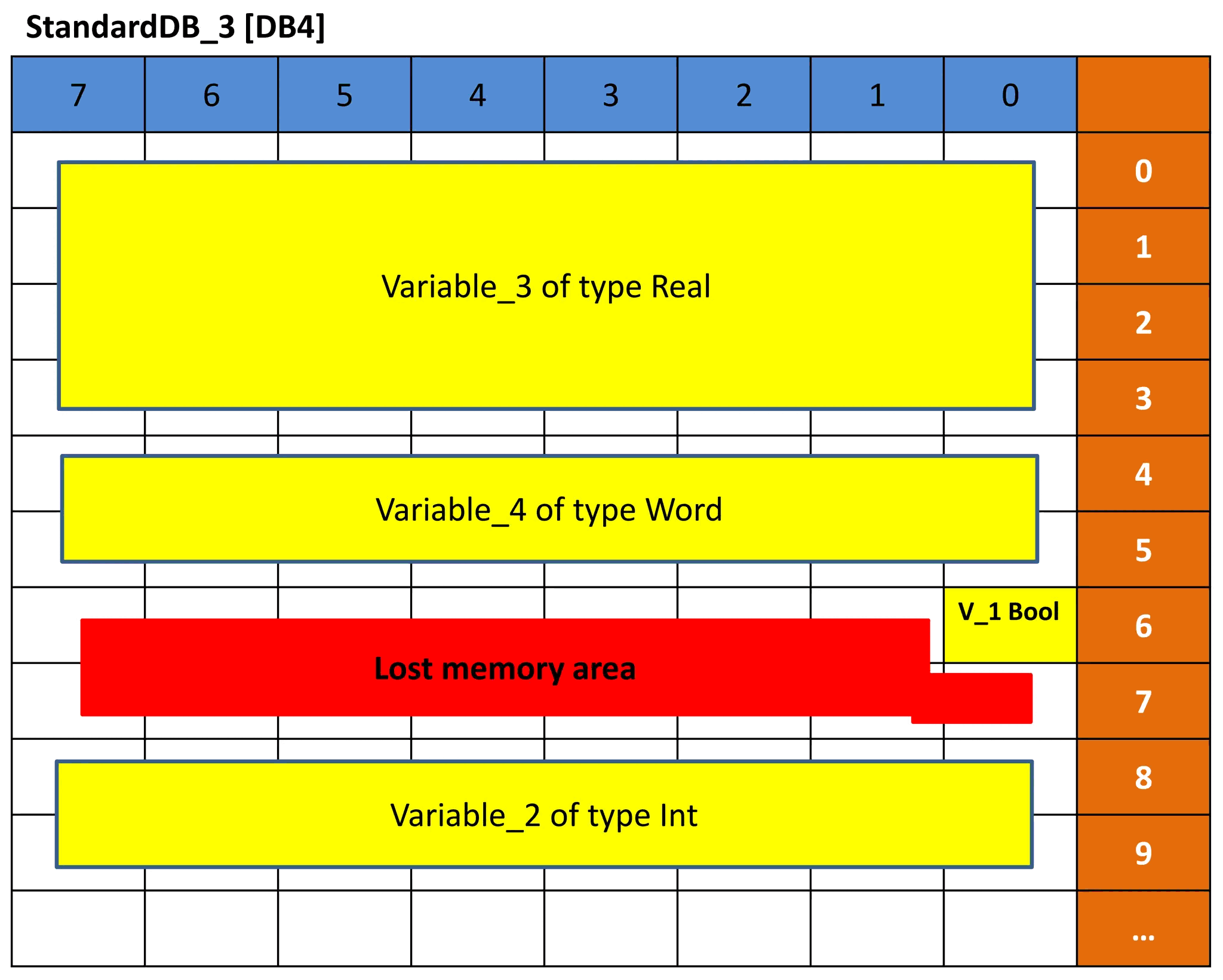
Bild 10 – Speicherdarstellung von DB4
Wenn Sie also mit einer Standard-DB arbeiten, müssen Sie beim Deklarieren Ihrer Variablen vorsichtig sein, da Sie wissen, dass jedes Mal, wenn Sie eine neue BOOL-Variable definieren, Speicher verloren geht.
Wenn Sie die neue Variable am Ende Ihrer DB-Liste deklarieren, wird der Offset erweitert, um Ihre neue Variable einzuschließen. Wenn Sie die neue Variable jedoch zwischen Ihrer alten oder am Anfang der DB deklarieren, geschieht etwas anderes. Siehe Bild 11.

Bild 11 – Deklarieren einer neuen Variable
Als Erstes werden Sie feststellen, dass Ihr Offset jetzt verloren ist und Sie Ihren Code kompilieren müssen, um den neuen Offset wiederherzustellen. Siehe Bild 12.

Bild 12 – Stellen Sie Ihren Offset wieder her, indem Sie Ihren Code neu kompilieren
Ist Ihnen aufgefallen, wie sich die Adressierung der Variablen (OFFSET) geändert hat?
Beispielsweise war der Offset des REAL-Tags 2,0, aber nachdem wir die neue Testvariable hinzugefügt haben, ist die Adressierung desselben REAL-Tags (OFFSET) jetzt 4,0, siehe Bild 13.

Bild 13 – Offset-Änderung nach dem Hinzufügen der Testvariable
Beim Hinzufügen einer neuen Variable wurde also die Adressierung aller alten Variablen geändert. Das bedeutet, dass jede Anweisung in Ihrem Programm, die den Wert einer bestimmten Variable schreiben oder lesen muss, jetzt die zugewiesene Adresse in der Anweisung betrachtet, aber jetzt hat die Adresse andere Daten als erwartet.
Einfach ausgedrückt ist Ihre gesamte Logik jetzt durcheinander. Das wird zu einer Menge Ärger führen. Ganz zu schweigen davon, dass Sie jetzt zusätzlichen Speicher verloren haben, nachdem Sie die neue Variable hinzugefügt haben. Siehe Bild 14.

Bild 14 – Hinzufügen einer MOVE-Anweisung
Fügen wir eine MOVE-Anweisung hinzu, um einen Wert von 1 in das Tag Variable_2 zu verschieben. Sehen Sie, dass die Adresse der MOVE-Ausgabe %DB2.DBW2 lautet.
Fügen wir nun eine neue Variable vom Typ INT zu DB2 hinzu. Siehe Bild 15.

Bild 15 – Neue INT-Variable hinzufügen
Wenn Sie die neue Variable hinzufügen, geht der Offset verloren und die SPS weiß nicht mehr, wo das Ziel von OUT1 der MOVE-Anweisung ist.
Wir müssen das Programm kompilieren, um den neuen Offset neu zu laden. Siehe Bild 16.

Bild 16 – Neue Adresse von OUT1
Sehen Sie, wie sich die OUT1-Adresse jetzt geändert hat? Es ist jetzt %DB2.DBW4 statt %DB2.DBW2. Dies ist ein sehr großer Nachteil bei der Verwendung von Standarddatenblöcken.
Was sind optimierte DBs?
Der Unterschied zwischen optimierten Datenblöcken und Standarddatenblöcken besteht darin, dass Variablen in einem optimierten Datenblock keiner festen Adresse zugewiesen werden, sondern den Variablen ein symbolischer Name zugewiesen wird. Außerdem ist die Struktur des Datenblocks nicht so festgelegt wie bei den Standarddatenblöcken, sodass beim Deklarieren neuer Tags kein Speicherverlust auftritt und die Adressen nicht geändert werden. Siehe Abbildung 17.

Abbildung 17 – Deklarieren neuer Tags in optimierten Blöcken
Das Deklarieren neuer Tags in optimierten Datenblöcken wirkt sich also nicht auf die übrigen Tags aus, da diese durch symbolische Namen und nicht durch absolute Adressierung definiert werden.
Ein optimierter Datenblock erlaubt Ihnen nicht, Adressen zu verwenden, wenn Sie mit den darin definierten Tags arbeiten. Siehe Bild 18.

Bild 18 – Absolute Adressierung bei optimierten Bausteinen
Wie Sie im letzten Bild sehen, ist bei einem optimierten Datenbaustein keine absolute Adressierung erlaubt und nur symbolische Namen sind zulässig. Siehe Bild 19.

Bild 19 – Verwendung symbolischer Namen bei optimierten DBs
Vorteile von Datenbausteinen mit optimiertem Zugriff
Datenbausteine mit optimiertem Zugriff haben keine fest definierte Struktur. Den Datenelementen (Tags) wird nur ein symbolischer Name zugewiesen und es wird keine feste Adresse innerhalb des Bausteins verwendet.
Die Elemente werden automatisch im verfügbaren Speicherbereich des Bausteins gespeichert, so dass keine Lücken im Speicher entstehen. Dadurch wird die Speicherkapazität optimal ausgenutzt und Speicherverlust im Vergleich zu Standard-DBs vermieden.
Dadurch ergeben sich folgende Vorteile:
- Sie können Datenbausteine mit beliebiger Struktur erstellen, ohne auf die physikalische Anordnung der einzelnen Variablen zu achten.
- Ein schneller Zugriff auf die optimierten Daten ist jederzeit möglich, da die Datenablage vom System optimiert und verwaltet wird.
- Zugriffsfehler, wie beispielsweise bei indirekter Adressierung oder vom HMI aus, sind nicht möglich. Denn es gibt keine Adressen, sondern nur eindeutige symbolische Namen für jede Variable.
- Sie können bestimmte einzelne Variablen als remanent definieren. In Standard-DBs können Sie nur den gesamten Baustein als remanent definieren.
Fazit
Optimierte Datenbausteine haben viele Vorteile gegenüber Standard-DBs. Durch die Verwendung symbolischer Namen können Adressänderungen von Variablen vermieden werden, wenn Sie Ihrem Baustein neue Variablen hinzufügen.
Bei optimierten Bausteinen geht kein Speicherbereich verloren. Ganz im Gegensatz zu dem, was bei der Verwendung von Standard-DBs passiert.