
In the previous article, we talked about data blocks, and we discussed the two different types of data blocks, the global data block and the data instances of function blocks FBs.
In this article, we are going to discuss what is meant by optimized data block access and standard data block access in Siemens Tia Portal.
Contents:
- What are optimized and standard data blocks?
- Simple program example.
- What are Standard DBs? What is the offset?
- What are optimized DBs?
- Advantages of using optimized DBs.
- Conclusions.
What is optimized and standard data block access?
First, these are not new types of data blocks; we said we only have two different types, the global DB and the instance DB. Optimized data block access is a feature for the data block. You can activate or disable this feature from the properties of the data block you have created.
The optimized data block feature is only available for S7-1200 and S7-1500 PLCs not for s7-300 or s7-400
The standard setting for data blocks when working with S7-1200 or S7-1500 PLCs is that they are optimized, if you want a standard data block you will have to set that yourself.
So, what is optimized and standard blocks? To understand the difference, we will make a simple program and try to show how an optimized block differs from a standard block.
Simple Program Example:
In this example we will not create any PLC logic or code any instructions, we will just create 2 global data blocks, DB1 will be called OptimizedDB and DB2 will be called StandardDB.
Inside both data blocks, we will declare 4 variables of data types Bool, Int, Real, and Word respectively. See picture 1.

Picture 1 – Create two global DBs
The first thing you will notice is that both data blocks are exactly the same, that is because as we said the default setting when creating a data block is that it will be optimized, so we need to change the setting of DB2 to make it a standard block, to see if something will change.
We do that from the properties of that DB2. You access the properties of DB2 by right click the data block and press properties. See picture 2.

Picture 2 – Change DB2 to standard block access
Once you de-select the optimized block access attributes that you see in picture 2 and press OK, a warning message will pop up, see picture 3.

Picture 3 – Change block access Pop-up
Once you press OK, your DB2 will have been converted to standard block access. See picture 4. To see what difference did that make.

Picture 4 – DB2 is now a standard block
What we can directly see is that DB1 and DB2 are not the same anymore. The standard block access option represented in DB2 has an additional column called offset.
In front of each variable in the offset box, there is a … written, this will change once you compile your program.
Let’s compile and see what happens, see picture 5.

Picture 5 – Compile your program to reload the offset
Now, the offset is filled in with as you can see 0.0, 2.0, 4.0, and 8.0 respectively.
So, what is that offset? What does it mean? We will get to that later, but now, Let’s create another STANDARD block and declare the same 4 variables, but this time we will change the order of the variable data types, see picture 6.

Picture 6 – Create another standard block DB3
You see from the last picture the offset of DB2 and DB3 is different, why the offset values are different when we changed the order of data types? They are the same data types but in different order.
Let’s create another standard DB, and declare the same 4 variables but again in a different order. Compile your PLC code and now compare the offset of the 3 DBs. See picture 7.

Picture 7 – Three different DBs with three different offsets
The same thing happened again.
What are Standard DBs? What is the offset?
Data blocks with standard access have a fixed structure. When you declare a variable inside a standard DB this variable will be assigned a fixed address within this DB.
The address of this variable is shown in the “Offset” column. So, what we were seeing inside the offset in previous pictures was the address assigned for each variable.
Because the structure of standard DBs is fixed, you can only work inside the DBs with fixed memory capacity, this is 16 bits area or 2 bytes. This is the reason for the different addressing of the same variables when we changed the order of declaration. For more explanation see picture 8.
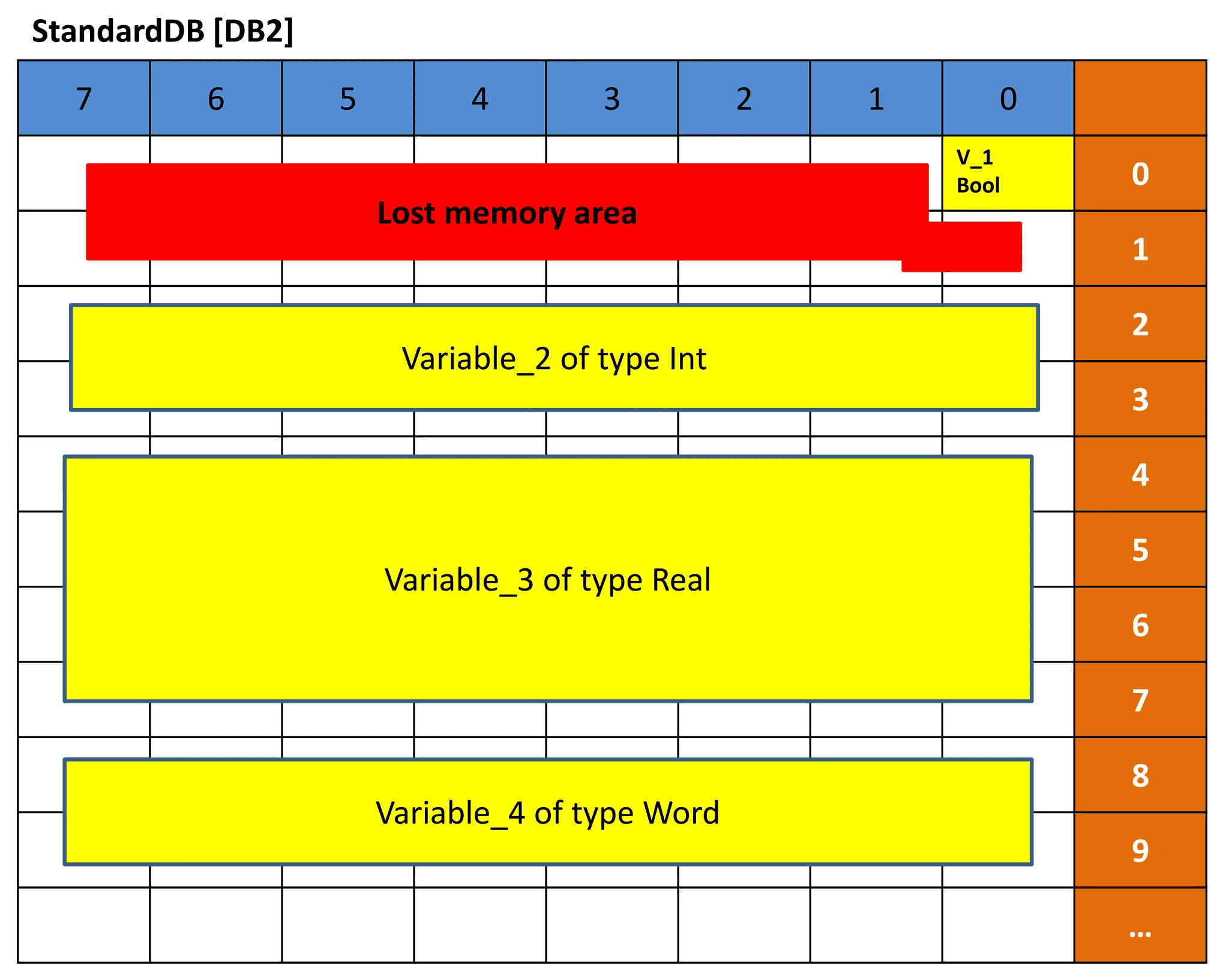
Picture 8 – Simple representation of DB2
Picture 8 shows a simple representation of the standard data block DB2. As we said before a standard DB has fixed memory blocks of 16 bits, so, when we declare Variable_1 to be of data type BOOL, this Variable will occupy the whole 16 bits even though it only needs a 1-bit memory. That is why you see the rest of the area marked red because it is not used but can no longer be used. So it is a lost memory.
With Variable_2 the data type INT needs 16 bits, so it is using 2 whole bytes. Same with Variable_4 which is of data type WORD.
With Variable_3 we occupied 4 bytes because it is of data type REAL. This is why the offset for DB2 is 0.0, 2.0, 4.0, and 8.0 respectively.
The same concept is executed for DB3 and DB4. But because the data type order of the variables is different the memory representation will be different and hence the offset will be different. See pictures 9 and 10 for DB3 and DB4. See if you can understand the representation based on the previous explanation.
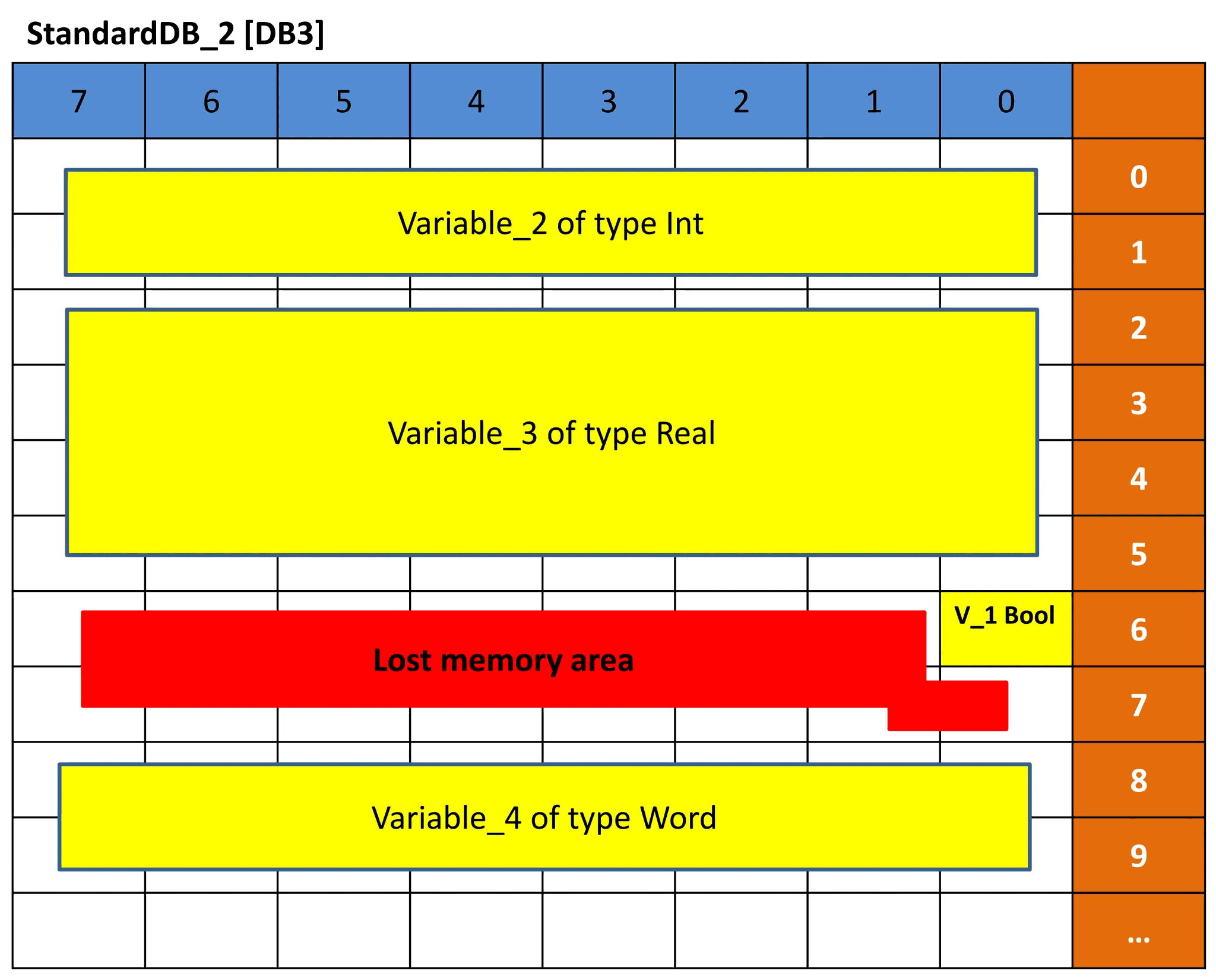
Picture 9 – Memory representation of DB3
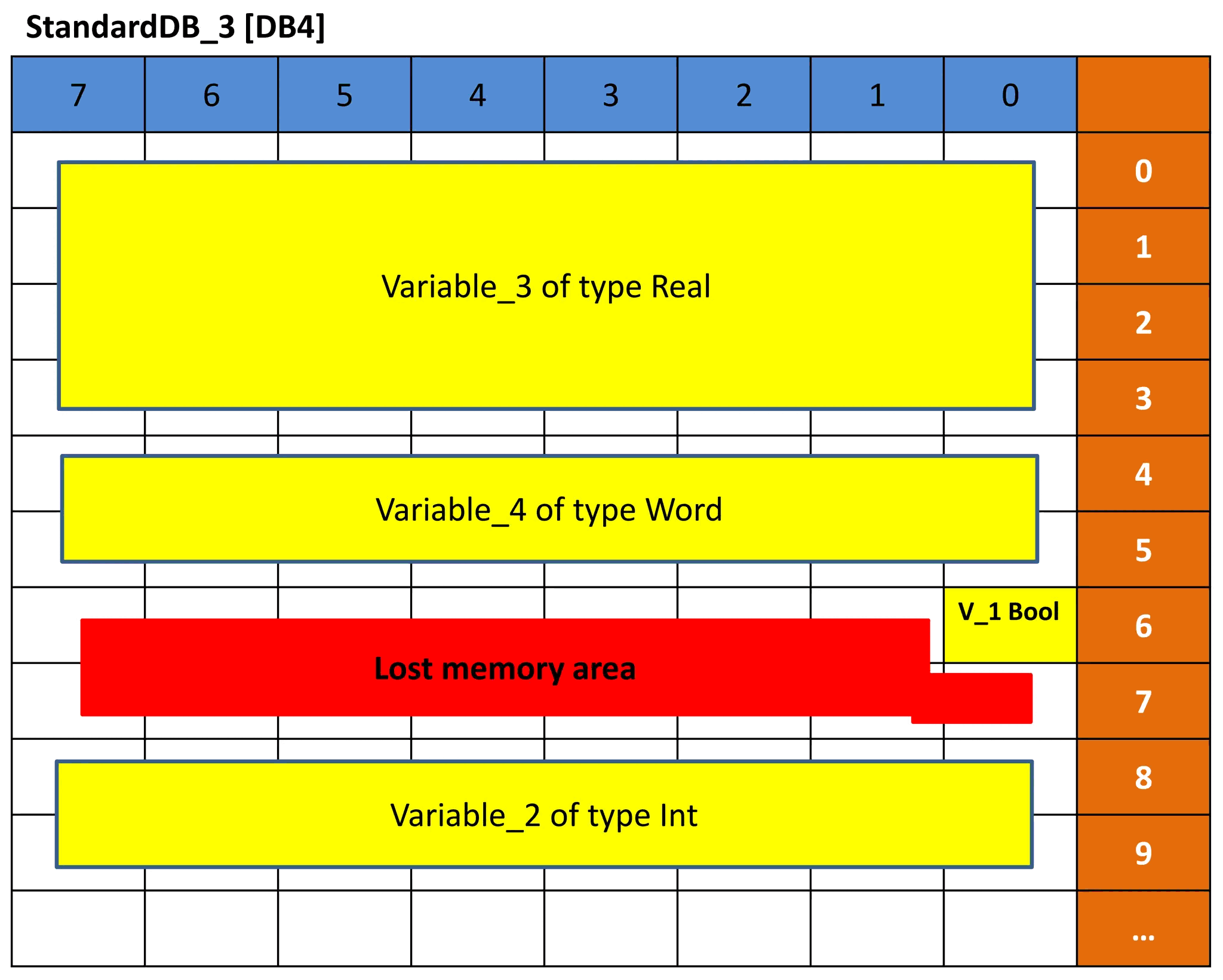
Picture 10 – Memory representation of DB4
So, when you work with a standard DB you have to be careful when declaring your variables, knowing that there would be a loss of memory each time you define a new BOOL variable.
If you declare the new variable at the end of your DB list, the offset will extend to include your new variable. But if you declare the new variable between your old or at the start of the DB something else will happen. See picture 11.

Picture 11 – Declare a new variable
The first thing you will notice is that your offset is now lost, and you have to compile your code to re-establish the new offset. See picture 12.

Picture 12 – Re-establish your offset by recompiling your code
Did you notice how the addressing of the Variables (OFFSET) has now changed?
For example, the offset of the REAL tag was 2.0 but after we added the new TestVariable the addressing of the same REAL tag (OFFSET) is now 4.0, see picture 13.

Picture 13 – Offset change after adding TestVariable
So, when adding a new variable the addressing of all old variables was changed. That means any instruction in your program that need to write of read the value of a certain variable will now be looking at the assigned address in the instruction but now the address has different data than expected.
So simply put, your whole logic is now messed up. That will lead to a lot of trouble. Not to mention now you have extra lost memory after you added the new variable. See picture 14.

Picture 14 – Add a MOVE instruction
Let’s add a MOVE instruction to move a value of 1 into the Variable_2 tag. See how the address of the MOVE output is %DB2.DBW2.
Now, let’s add a new variable of type INT to DB2. See picture 15.

Picture 15 – Add new INT variable
When you add the new variable, the offset is lost and the PLC no longer knows where the destination of the OUT1 of the MOVE instruction is.
We need to compile the program to reload the new offset. See picture 16.

Picture 16 – New address of OUT1
Do you see how the OUT1 address is now different? It is now %DB2.DBW4 instead of %DB2.DBW2. This is a very big disadvantage of using standard data blocks.
What are Optimized DBs?
The difference between optimized data blocks and standard data blocks is that variables inside an optimized data block are not assigned to a fixed address, but rather a symbolic name is given for the variables, plus the structure of the data block is not fixed as the standard data blocks, so there is no memory loss and no change in the addresses when declaring new tags. See picture 17.

Picture 17 – Declaring new tag in optimized blocks
So, declaring new tags in optimized data blocks will not affect the rest of the tags, as they are defined by symbolic names rather than absolute addressing.
An optimized data block will not allow you to use addresses when working with the tags defined inside of it. See picture 18.

Picture 18 – Absolute addressing with optimized blocks
As you see in the last picture, absolute addressing is not allowed with an optimized data block and only symbolic names are allowed. See picture 19.

Picture 19 – Using symbolic names with optimized DBs
Advantages of Data blocks with Optimized Access
Data blocks with optimized access have no fixed defined structure. The data elements (tags) are assigned only a symbolic name and no fixed address within the block is used.
The elements are saved automatically in the available memory area of the block so that there are no gaps in the memory. This makes for optimal use of the memory capacity and avoids lost memory compared to standard DBs.
This provides the following advantages:
- You can create data blocks with any structure without paying attention to the physical arrangement of the individual tags.
- Quick access to the optimized data is always available because the data storage is optimized and managed by the system.
- Access errors, as with indirect addressing or from the HMI, for example, are not possible. Because there are now addresses, just unique symbolic names for each tag.
- You can define specific individual tags as retentive. In standard DBs you can only define the whole block as retentive.
Conclusion
Optimized data blocks have a lot of advantages compared to standard DBs. Using symbolic names helps avoid any address changes of tags when adding new variables to your block.
With optimized blocks, no memory area is lost. Opposite of what happens when using standard DBs.
Recommended Comments
There are no comments to display.
Create an account or sign in to comment
You need to be a member in order to leave a comment
Create an account
Sign up for a new account in our community. It's easy!
Register a new accountSign in
Already have an account? Sign in here.
Sign In Now