
En el artículo anterior, hablamos sobre bloques de datos y analizamos los dos tipos diferentes de bloques de datos, el bloque de datos global y las instancias de datos de los bloques de función FB.
En este artículo, vamos a analizar qué se entiende por acceso a bloques de datos optimizado y acceso a bloques de datos estándar en Siemens Tia Portal.
Contenido:
- ¿Qué son los bloques de datos estándar y optimizados?
- Ejemplo de programa simple.
- ¿Qué son las bases de datos estándar? ¿Qué es el offset?
- ¿Qué son las bases de datos optimizadas?
- Ventajas de utilizar bases de datos optimizadas.
- Conclusiones.
¿Qué es el acceso a bloques de datos estándar y optimizado?
En primer lugar, estos no son nuevos tipos de bloques de datos; dijimos que solo tenemos dos tipos diferentes, la base de datos global y la base de datos de instancia. El acceso a bloques de datos optimizado es una característica del bloque de datos. Puede activar o desactivar esta característica desde las propiedades del bloque de datos que ha creado.
La función de bloque de datos optimizado solo está disponible para los PLC S7-1200 y S7-1500, no para los S7-300 o S7-400
La configuración estándar para los bloques de datos cuando se trabaja con PLC S7-1200 o S7-1500 es que estén optimizados; si desea un bloque de datos estándar, deberá configurarlo usted mismo.
Entonces, ¿qué son los bloques optimizados y los bloques estándar? Para comprender la diferencia, crearemos un programa simple e intentaremos mostrar en qué se diferencia un bloque optimizado de un bloque estándar.
Ejemplo de programa simple:
En este ejemplo, no crearemos ninguna lógica de PLC ni codificaremos ninguna instrucción, solo crearemos 2 bloques de datos globales, DB1 se llamará OptimizedDB y DB2 se llamará StandardDB.
Dentro de ambos bloques de datos, declararemos 4 variables de tipos de datos Bool, Int, Real y Word respectivamente. Vea la imagen 1.

Imagen 1: crear dos bases de datos globales
Lo primero que notará es que ambos bloques de datos son exactamente iguales, esto se debe a que, como dijimos, la configuración predeterminada al crear un bloque de datos es que se optimizará, por lo que debemos cambiar la configuración de DB2 para convertirlo en un bloque estándar, para ver si algo cambia.
Lo hacemos desde las propiedades de ese DB2. Acceda a las propiedades de DB2 haciendo clic derecho en el bloque de datos y presione Propiedades. Vea la imagen 2.

Imagen 2: cambiar DB2 al acceso estándar al bloque
Una vez que desmarque los atributos de acceso optimizado al bloque que ve en la imagen 2 y presione Aceptar, aparecerá un mensaje de advertencia, vea la imagen 3.

Imagen 3: ventana emergente para cambiar el acceso al bloque
Una vez que presione Aceptar, su DB2 se habrá convertido al acceso estándar al bloque. Vea la imagen 4 para ver qué diferencia generó.

Imagen 4: DB2 ahora es un bloque estándar
Lo que podemos ver directamente es que DB1 y DB2 ya no son lo mismo. La opción de acceso al bloque estándar representada en DB2 tiene una columna adicional llamada desplazamiento.
Delante de cada variable en el cuadro de desplazamiento, hay un … escrito, esto cambiará una vez que compile su programa.
Vamos a compilar y ver qué sucede, vea la imagen 5.

Imagen 5: compile su programa para recargar el desplazamiento
Ahora, el desplazamiento se completa con, como puede ver, 0.0, 2.0, 4.0 y 8.0 respectivamente.
Entonces, ¿qué es ese desplazamiento? ¿Qué significa? Llegaremos a eso más tarde, pero ahora, vamos a crear otro bloque ESTÁNDAR y declarar las mismas 4 variables, pero esta vez cambiaremos el orden de los tipos de datos de las variables, vea la imagen 6.

Imagen 6: crear otro bloque estándar DB3
En la última imagen, puede ver que el desplazamiento de DB2 y DB3 es diferente. ¿Por qué los valores de desplazamiento son diferentes cuando cambiamos el orden de los tipos de datos? Son los mismos tipos de datos, pero en un orden diferente.
Creemos otra base de datos estándar y declaremos las mismas 4 variables, pero nuevamente en un orden diferente. Compile su código de PLC y ahora compare el desplazamiento de las 3 bases de datos. Vea la imagen 7.

Imagen 7: tres bases de datos diferentes con tres desplazamientos diferentes
Ocurrió lo mismo nuevamente.
¿Qué son las bases de datos estándar? ¿Cuál es el desplazamiento?
Los bloques de datos con acceso estándar tienen una estructura fija. Cuando declaras una variable dentro de una base de datos estándar, a esta variable se le asignará una dirección fija dentro de esta base de datos.
La dirección de esta variable se muestra en la columna “Offset”. Por lo tanto, lo que estábamos viendo dentro del offset en las imágenes anteriores era la dirección asignada para cada variable.
Como la estructura de las bases de datos estándar es fija, solo puedes trabajar dentro de las bases de datos con capacidad de memoria fija, es decir, un área de 16 bits o 2 bytes. Esta es la razón por la que las mismas variables se direccionan de manera diferente cuando cambiamos el orden de declaración. Para obtener más explicaciones, consulta la imagen 8.
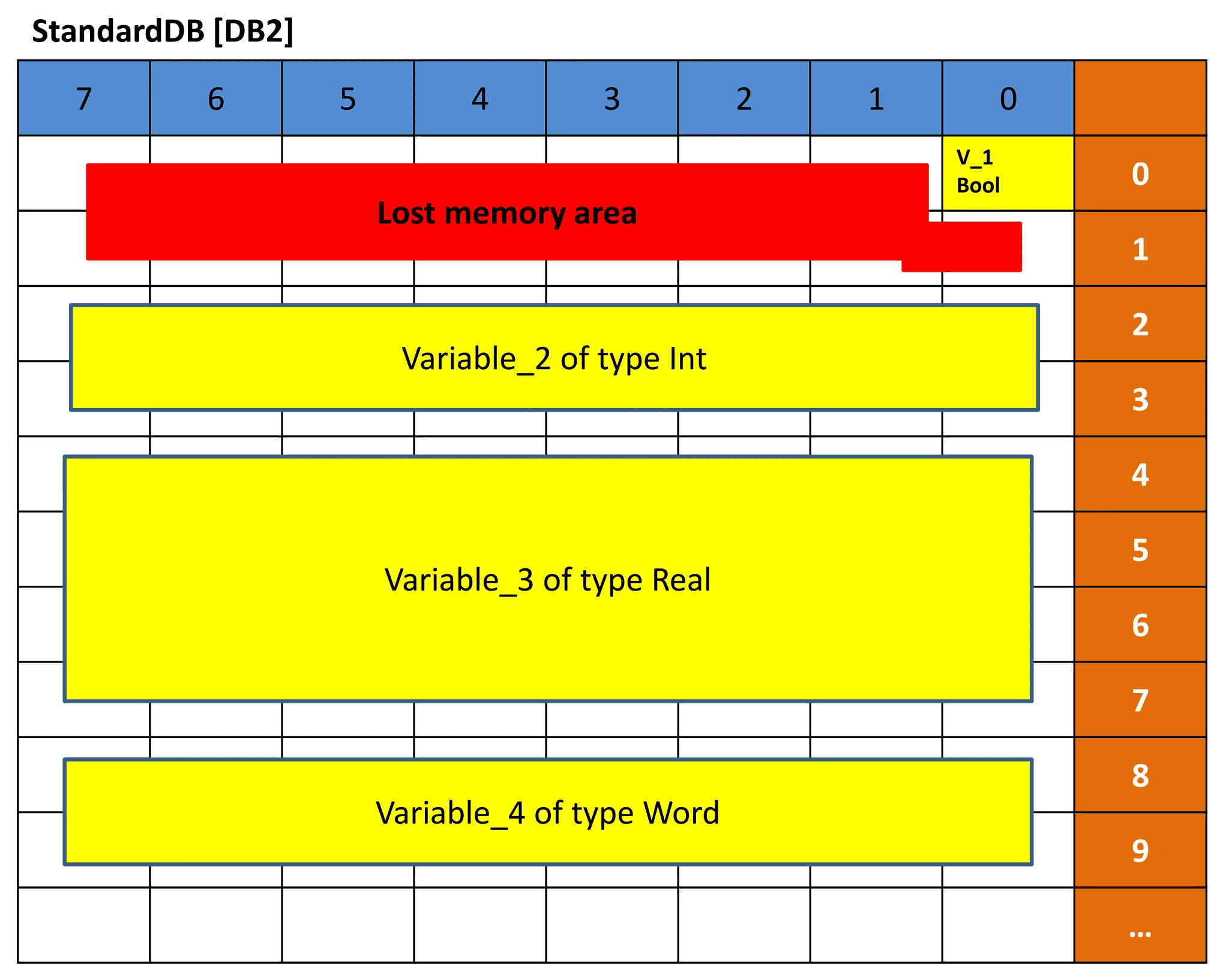
Imagen 8: representación simple de DB2
La imagen 8 muestra una representación simple del bloque de datos estándar DB2. Como dijimos antes, una base de datos estándar tiene bloques de memoria fijos de 16 bits, por lo que, cuando declaramos que la Variable_1 es del tipo de datos BOOL, esta Variable ocupará los 16 bits completos aunque solo necesite 1 bit de memoria. Por eso, el resto del área se ve marcada en rojo porque no se usa pero ya no se puede usar. Por lo tanto, es una memoria perdida.
Con la Variable_2, el tipo de datos INT necesita 16 bits, por lo que está utilizando 2 bytes completos. Lo mismo con la Variable_4, que es del tipo de datos WORD.
Con la Variable_3, ocupamos 4 bytes porque es del tipo de datos REAL. Por eso, el desplazamiento para DB2 es 0.0, 2.0, 4.0 y 8.0 respectivamente.
El mismo concepto se ejecuta para DB3 y DB4. Pero debido a que el orden de los tipos de datos de las variables es diferente, la representación de la memoria será diferente y, por lo tanto, el desplazamiento será diferente. Vea las imágenes 9 y 10 para DB3 y DB4. Vea si puede comprender la representación en función de la explicación anterior.
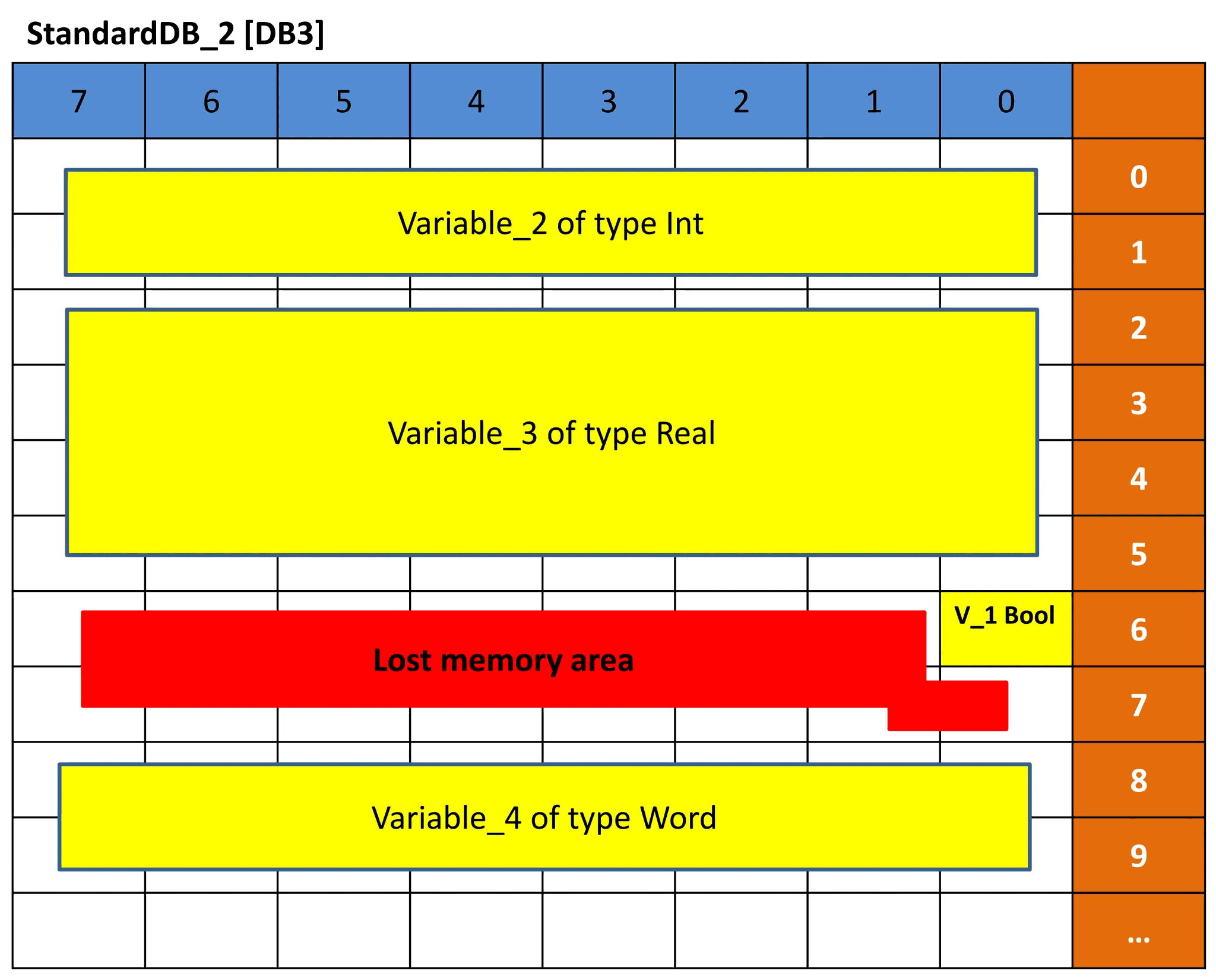
Imagen 9: representación de la memoria de DB3
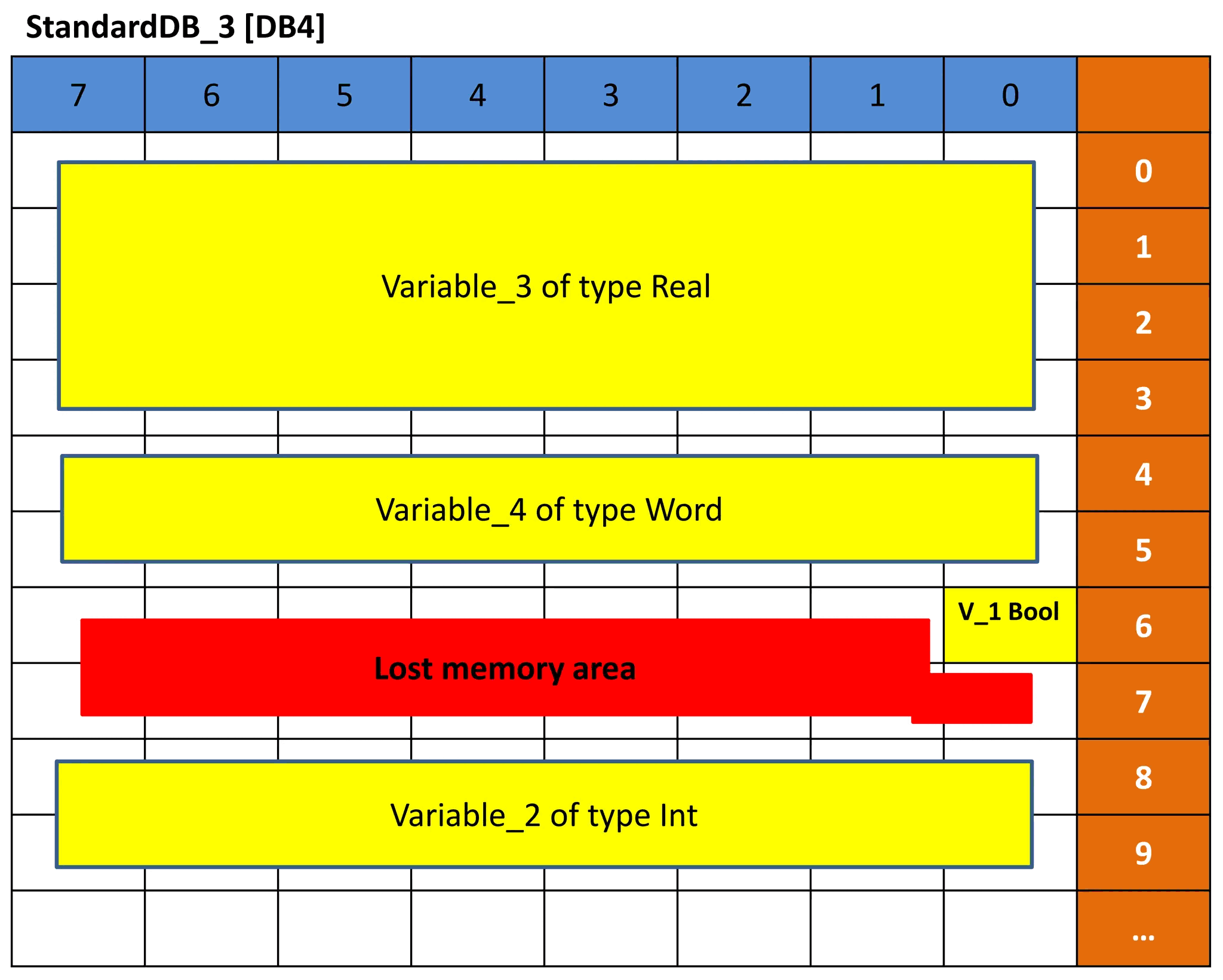
Imagen 10: representación de la memoria de DB4
Por lo tanto, cuando trabaja con una base de datos estándar, debe tener cuidado al declarar sus variables, sabiendo que habrá una pérdida de memoria cada vez que defina una nueva variable BOOL.
Si declara la nueva variable al final de su lista de base de datos, el desplazamiento se extenderá para incluir su nueva variable. Pero si declara la nueva variable entre su antigua o al comienzo de la base de datos, sucederá algo más. Vea la imagen 11.

Imagen 11: Declaración de una nueva variable
Lo primero que notará es que su desplazamiento ahora se perdió y debe compilar su código para restablecer el nuevo desplazamiento. Vea la imagen 12.

Imagen 12: restablezca su desplazamiento recompilando su código
¿Observó cómo ha cambiado ahora el direccionamiento de las variables (OFFSET)?
Por ejemplo, el desplazamiento de la etiqueta REAL era 2.0, pero después de agregar la nueva variable de prueba, el direccionamiento de la misma etiqueta REAL (OFFSET) ahora es 4.0, vea la imagen 13.

Imagen 13: cambio de desplazamiento después de agregar la variable de prueba
Entonces, al agregar una nueva variable, se cambió el direccionamiento de todas las variables antiguas. Eso significa que cualquier instrucción en su programa que necesite escribir o leer el valor de una determinada variable ahora buscará en la dirección asignada en la instrucción, pero ahora la dirección tiene datos diferentes a los esperados.
En pocas palabras, toda su lógica ahora está desordenada. Eso generará muchos problemas. Sin mencionar que ahora tiene memoria extra perdida después de agregar la nueva variable. Vea la imagen 14.

Imagen 14: agregar una instrucción MOVE
Agreguemos una instrucción MOVE para mover un valor de 1 a la etiqueta Variable_2. Observe cómo la dirección de la salida MOVE es %DB2.DBW2.
Ahora, agreguemos una nueva variable de tipo INT a DB2. Vea la imagen 15.

Imagen 15: agregar una nueva variable INT
Cuando agrega la nueva variable, se pierde el desplazamiento y el PLC ya no sabe dónde está el destino de OUT1 de la instrucción MOVE.
Necesitamos compilar el programa para volver a cargar el nuevo desplazamiento. Vea la imagen 16.

Imagen 16: nueva dirección de OUT1
¿Ve cómo la dirección de OUT1 ahora es diferente? Ahora es %DB2.DBW4 en lugar de %DB2.DBW2. Esta es una gran desventaja de usar bloques de datos estándar.
¿Qué son las bases de datos optimizadas?
La diferencia entre los bloques de datos optimizados y los bloques de datos estándar es que las variables dentro de un bloque de datos optimizado no se asignan a una dirección fija, sino que se les da un nombre simbólico, además la estructura del bloque de datos no es fija como los bloques de datos estándar, por lo que no hay pérdida de memoria ni cambios en las direcciones al declarar nuevas etiquetas. Ver imagen 17.

Imagen 17: Declaración de nueva etiqueta en bloques optimizados
Por lo tanto, declarar nuevas etiquetas en bloques de datos optimizados no afectará al resto de las etiquetas, ya que se definen por nombres simbólicos en lugar de direcciones absolutas.
Un bloque de datos optimizado no le permitirá usar direcciones cuando trabaje con las etiquetas definidas dentro de él. Consulte la imagen 18.

Imagen 18: direccionamiento absoluto con bloques optimizados
Como puede ver en la última imagen, no se permite el direccionamiento absoluto con un bloque de datos optimizado y solo se permiten nombres simbólicos. Consulte la imagen 19.

Imagen 19: uso de nombres simbólicos con bases de datos optimizadas
Ventajas de los bloques de datos con acceso optimizado
Los bloques de datos con acceso optimizado no tienen una estructura definida fija. A los elementos de datos (etiquetas) solo se les asigna un nombre simbólico y no se utiliza ninguna dirección fija dentro del bloque.
Los elementos se guardan automáticamente en el área de memoria disponible del bloque para que no haya espacios vacíos en la memoria. Esto permite un uso óptimo de la capacidad de memoria y evita la pérdida de memoria en comparación con las bases de datos estándar.
Esto proporciona las siguientes ventajas:
- Puede crear bloques de datos con cualquier estructura sin prestar atención a la disposición física de las etiquetas individuales.
- El acceso rápido a los datos optimizados está siempre disponible porque el almacenamiento de datos está optimizado y gestionado por el sistema.
- No es posible que se produzcan errores de acceso, como por ejemplo con el direccionamiento indirecto o desde la HMI. Como ahora hay direcciones, solo nombres simbólicos únicos para cada etiqueta.
- Puede definir etiquetas individuales específicas como retentivas. En las bases de datos estándar, solo puede definir todo el bloque como retentivo.
Conclusión
Los bloques de datos optimizados tienen muchas ventajas en comparación con las bases de datos estándar. El uso de nombres simbólicos ayuda a evitar cualquier cambio de dirección de las etiquetas al agregar nuevas variables a su bloque.
Con los bloques optimizados, no se pierde ningún área de memoria. Al contrario de lo que sucede cuando se utilizan bases de datos estándar.