
В предыдущей статье мы говорили о блоках данных и обсудили два различных типа блоков данных: глобальный блок данных и экземпляры данных функциональных блоков FB.
В этой статье мы обсудим, что подразумевается под оптимизированным доступом к блоку данных и стандартным доступом к блоку данных в Siemens Tia Portal.
Содержание:
- Что такое оптимизированные и стандартные блоки данных?
- Простой пример программы.
- Что такое стандартные базы данных? Что такое смещение?
- Что такое оптимизированные базы данных?
- Преимущества использования оптимизированных баз данных.
- Выводы.
Что такое оптимизированный и стандартный доступ к блоку данных?
Во-первых, это не новые типы блоков данных; мы сказали, что у нас есть только два различных типа: глобальный блок данных и экземплярный блок данных. Оптимизированный доступ к блоку данных — это функция для блока данных. Вы можете активировать или отключить эту функцию в свойствах созданного вами блока данных.
Функция оптимизированного блока данных доступна только для ПЛК S7-1200 и S7-1500, но не для s7-300 или s7-400
Стандартная настройка для блоков данных при работе с ПЛК S7-1200 или S7-1500 заключается в том, что они оптимизированы, если вам нужен стандартный блок данных, вам придется настроить это самостоятельно.
Итак, что такое оптимизированные и стандартные блоки? Чтобы понять разницу, мы создадим простую программу и попытаемся показать, чем оптимизированный блок отличается от стандартного блока.
Пример простой программы:
В этом примере мы не будем создавать никакой логики ПЛК или кодировать какие-либо инструкции, мы просто создадим 2 глобальных блока данных, DB1 будет называться OptimizedDB, а DB2 будет называться StandardDB.
Внутри обоих блоков данных мы объявим 4 переменные типов данных Bool, Int, Real и Word соответственно. См. рисунок 1.

Рисунок 1 – Создание двух глобальных баз данных
Первое, что вы заметите, это то, что оба блока данных абсолютно одинаковы, потому что, как мы уже говорили, настройка по умолчанию при создании блока данных заключается в том, что он будет оптимизирован, поэтому нам нужно изменить настройку DB2, чтобы сделать его стандартным блоком, и посмотреть, изменится ли что-то.
Мы делаем это из свойств этого DB2. Вы получаете доступ к свойствам DB2, щелкнув правой кнопкой мыши по блоку данных и нажав «Свойства». См. рисунок 2.

Рисунок 2 – Изменение DB2 на стандартный блочный доступ
После того, как вы отмените выбор оптимизированных атрибутов блочного доступа, которые вы видите на рисунке 2, и нажмете OK, появится предупреждающее сообщение, см. рисунок 3.

Рисунок 3 – Всплывающее окно изменения блочного доступа
После того, как вы нажмете OK, ваш DB2 будет преобразован в стандартный блочный доступ. См. рисунок 4. Чтобы увидеть, к чему это привело.

Рисунок 4 – DB2 теперь является стандартным блоком
Мы можем напрямую увидеть, что DB1 и DB2 больше не одно и то же. Параметр стандартного блочного доступа, представленный в DB2, имеет дополнительный столбец, называемый смещением.
Перед каждой переменной в поле смещения написано …, это изменится после компиляции вашей программы.
Давайте скомпилируем и посмотрим, что произойдет, см. рисунок 5.

Рисунок 5 — Скомпилируйте свою программу, чтобы перезагрузить смещение
Теперь смещение заполнено, как вы можете видеть, 0.0, 2.0, 4.0 и 8.0 соответственно.
Итак, что это за смещение? Что оно значит? Мы вернемся к этому позже, а сейчас давайте создадим еще один блок STANDARD и объявим те же 4 переменные, но на этот раз мы изменим порядок типов данных переменных, см. рисунок 6.

Рисунок 6 — Создадим еще один стандартный блок DB3
Вы видите из последнего рисунка, что смещение DB2 и DB3 отличается, почему значения смещения отличаются, когда мы изменили порядок типов данных? Это те же типы данных, но в другом порядке.
Давайте создадим еще один стандартный DB и объявим те же 4 переменные, но снова в другом порядке. Скомпилируйте код ПЛК и теперь сравните смещение 3 БД. Смотрите рисунок 7.

Рисунок 7 – Три разных БД с тремя разными смещениями
Снова произошло то же самое.
Что такое стандартные БД? Что такое смещение?
Блоки данных со стандартным доступом имеют фиксированную структуру. Когда вы объявляете переменную внутри стандартного БД, этой переменной будет назначен фиксированный адрес внутри этого БД.
Адрес этой переменной отображается в столбце «Смещение». Итак, то, что мы видели внутри смещения на предыдущих рисунках, было адресом, назначенным для каждой переменной.
Поскольку структура стандартных БД фиксирована, вы можете работать только внутри БД с фиксированным объемом памяти, это область 16 бит или 2 байта. Это причина разной адресации одних и тех же переменных, когда мы изменили порядок объявления. Для получения дополнительных объяснений см. рисунок 8.
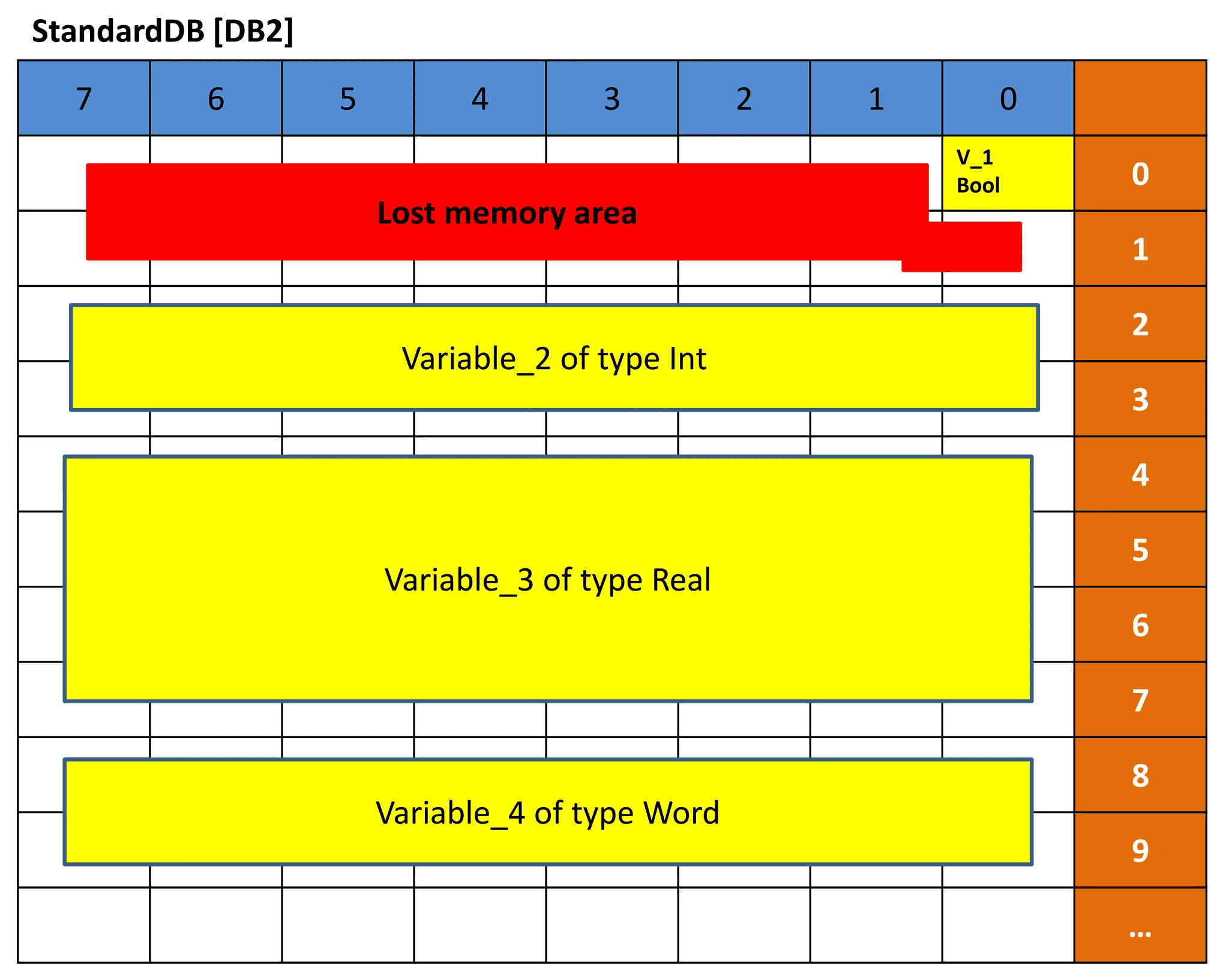
Рисунок 8 – Простое представление DB2
На рисунке 8 показано простое представление стандартного блока данных DB2. Как мы уже говорили, стандартная база данных имеет фиксированные блоки памяти по 16 бит, поэтому, когда мы объявляем Variable_1 как тип данных BOOL, эта Variable будет занимать все 16 бит, хотя ей нужна только 1-битная память. Вот почему вы видите оставшуюся область, отмеченную красным, потому что она не используется, но больше не может использоваться. Так что это потерянная память.
С Variable_2 тип данных INT требует 16 бит, поэтому он использует 2 целых байта. То же самое с Variable_4, который имеет тип данных WORD.
С Variable_3 мы заняли 4 байта, потому что он имеет тип данных REAL. Вот почему смещение для DB2 составляет 0.0, 2.0, 4.0 и 8.0 соответственно.
Та же концепция выполняется для DB3 и DB4. Но поскольку порядок типов данных переменных отличается, представление памяти будет отличаться, и, следовательно, смещение будет отличаться. Смотрите рисунки 9 и 10 для DB3 и DB4. Посмотрите, сможете ли вы понять представление на основе предыдущего объяснения.
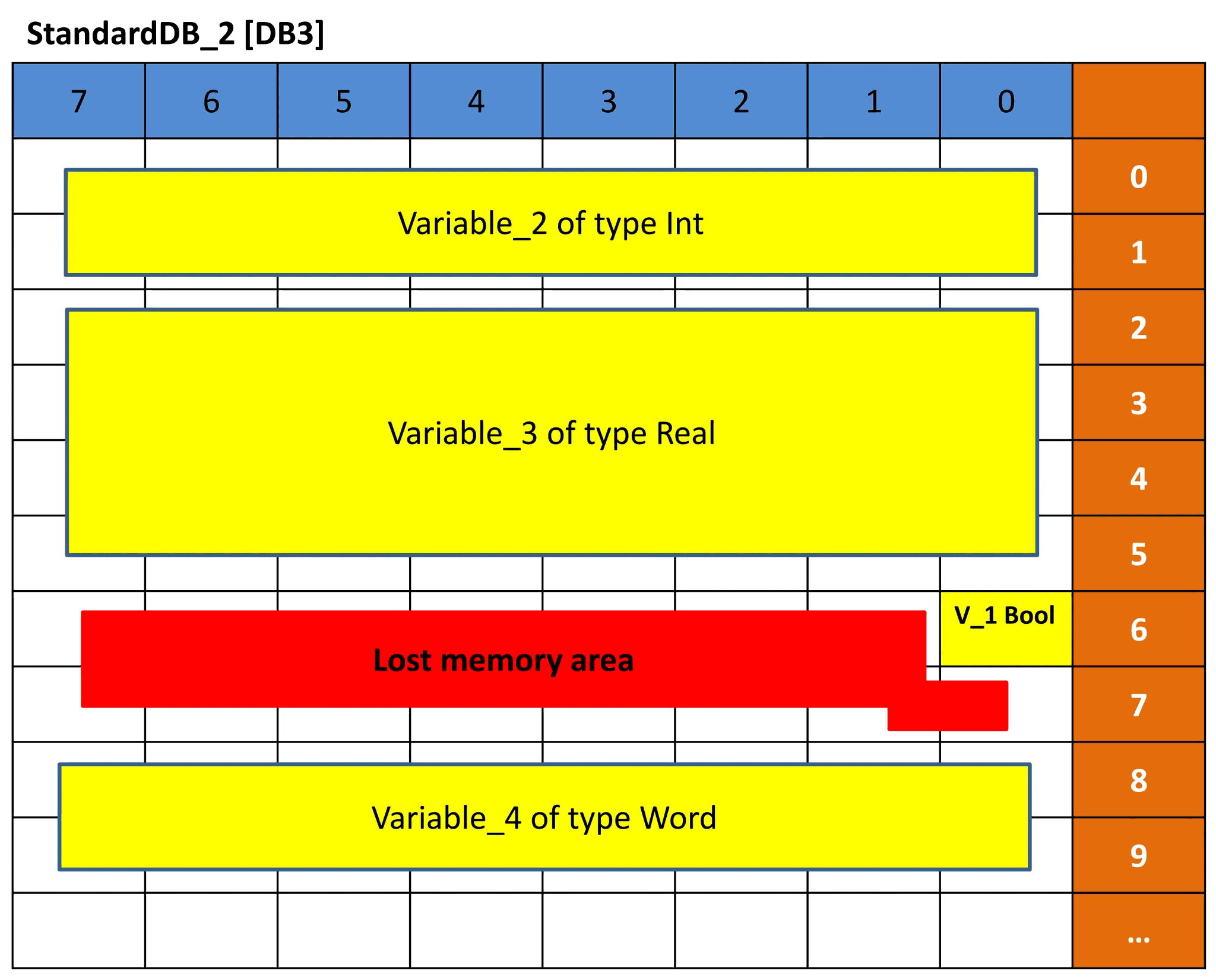
Рисунок 9 – Представление памяти DB3
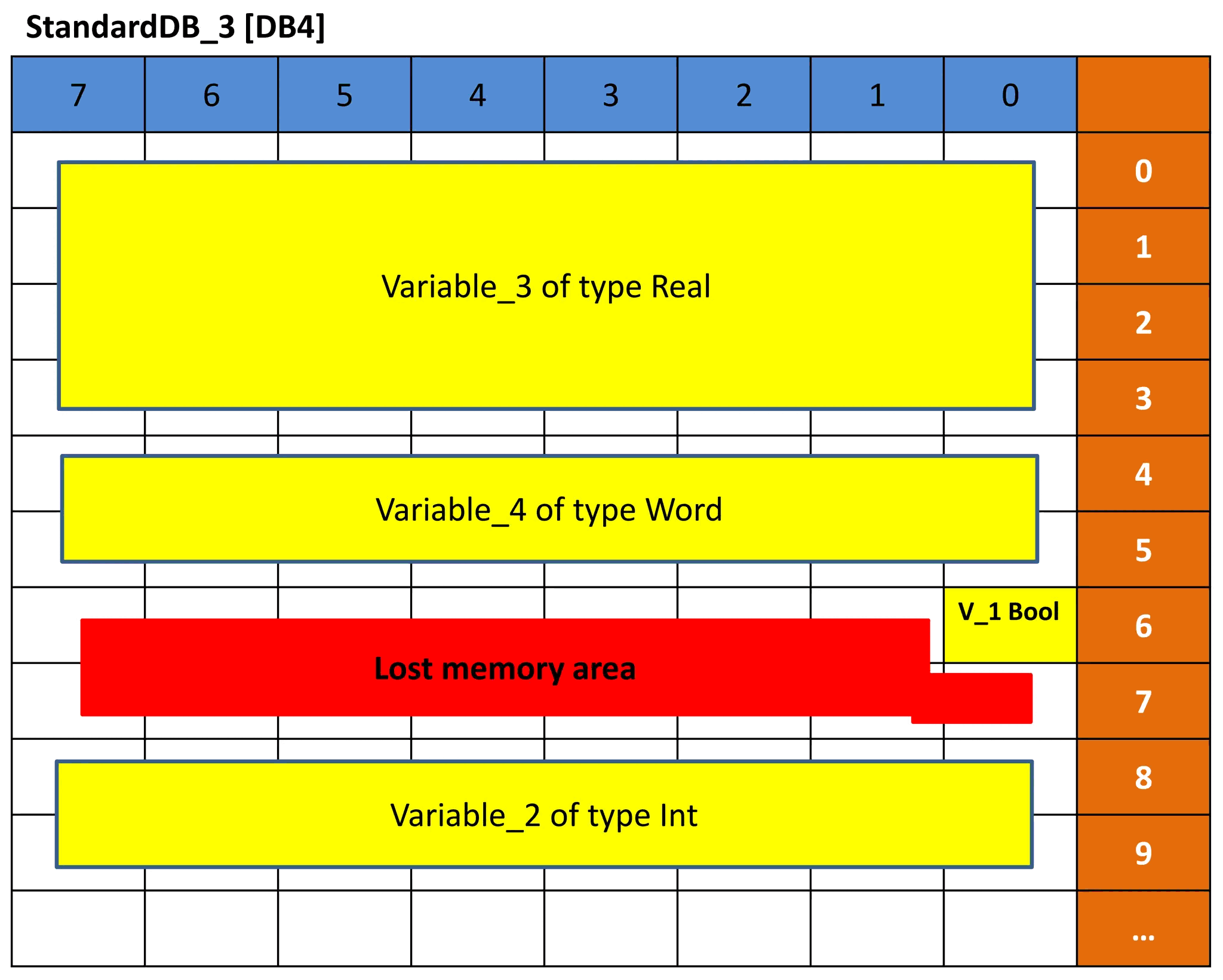
Рисунок 10 – Представление памяти DB4
Итак, когда вы работаете со стандартной DB, вы должны быть осторожны при объявлении переменных, зная, что будет потеря памяти каждый раз, когда вы определяете новую переменную BOOL.
Если вы объявите новую переменную в конце списка DB, смещение расширится, чтобы включить вашу новую переменную. Но если вы объявите новую переменную между старой или в начале DB, произойдет что-то еще. См. рисунок 11.

Рисунок 11 – Объявление новой переменной
Первое, что вы заметите, это то, что ваше смещение теперь потеряно, и вам придется скомпилировать свой код, чтобы заново установить новое смещение. См. рисунок 12.

Рисунок 12 – Повторно установите смещение, перекомпилировав свой код
Вы заметили, как теперь изменилась адресация переменных (OFFSET)?
Например, смещение тега REAL было 2.0, но после того, как мы добавили новую TestVariable, адресация того же тега REAL (OFFSET) теперь равна 4.0, см. рисунок 13.

Рисунок 13 – Изменение смещения после добавления TestVariable
Итак, при добавлении новой переменной адресация всех старых переменных была изменена. Это означает, что любая инструкция в вашей программе, которая должна записывать или считывать значение определенной переменной, теперь будет смотреть на назначенный адрес в инструкции, но теперь адрес имеет другие данные, чем ожидалось.
Проще говоря, вся ваша логика теперь испорчена. Это приведет к большим проблемам. Не говоря уже о том, что теперь у вас есть дополнительная потерянная память после добавления новой переменной. Смотрите рисунок 14.

Рисунок 14 — Добавление инструкции MOVE
Давайте добавим инструкцию MOVE для перемещения значения 1 в тег Variable_2. Посмотрите, как адрес вывода MOVE равен %DB2.DBW2.
Теперь давайте добавим новую переменную типа INT в DB2. См. рисунок 15.

Рисунок 15 – Добавление новой переменной INT
При добавлении новой переменной смещение теряется, и ПЛК больше не знает, где находится место назначения OUT1 инструкции MOVE.
Нам нужно скомпилировать программу, чтобы перезагрузить новое смещение. См. рисунок 16.

Рисунок 16 – Новый адрес OUT1
Вы видите, как теперь изменился адрес OUT1? Теперь это %DB2.DBW4 вместо %DB2.DBW2. Это очень большой недостаток использования стандартных блоков данных.
Что такое оптимизированные базы данных?
Разница между оптимизированными блоками данных и стандартными блоками данных заключается в том, что переменные внутри оптимизированного блока данных не назначаются фиксированному адресу, а вместо этого переменным дается символическое имя, плюс структура блока данных не фиксируется как у стандартных блоков данных, поэтому нет потери памяти и изменения адресов при объявлении новых тегов. Смотрите рисунок 17.

Рисунок 17 — Объявление нового тега в оптимизированных блоках
Таким образом, объявление новых тегов в оптимизированных блоках данных не повлияет на остальные теги, поскольку они определяются символическими именами, а не абсолютной адресацией.
Оптимизированный блок данных не позволит вам использовать адреса при работе с тегами, определенными внутри него. Смотрите рисунок 18.

Рисунок 18 — Абсолютная адресация с оптимизированными блоками
Как вы видите на последнем рисунке, абсолютная адресация не допускается с оптимизированным блоком данных, разрешены только символические имена. См. рисунок 19.

Рисунок 19 – Использование символических имен с оптимизированными БД
Преимущества блоков данных с оптимизированным доступом
Блоки данных с оптимизированным доступом не имеют фиксированной определенной структуры. Элементам данных (тегам) назначается только символическое имя, и фиксированный адрес внутри блока не используется.
Элементы автоматически сохраняются в доступной области памяти блока, так что в памяти нет пробелов. Это обеспечивает оптимальное использование объема памяти и позволяет избежать потери памяти по сравнению со стандартными БД.
Это обеспечивает следующие преимущества:
- Вы можете создавать блоки данных с любой структурой, не обращая внимания на физическое расположение отдельных тегов.
- Быстрый доступ к оптимизированным данным всегда доступен, поскольку хранилище данных оптимизировано и управляется системой.
- Ошибки доступа, например, при косвенной адресации или из HMI, невозможны. Поскольку теперь есть адреса, а только уникальные символические имена для каждого тега.
- Вы можете определить отдельные теги как сохраняемые. В стандартных БД вы можете определить только весь блок как сохраняемый.
Заключение
Оптимизированные блоки данных имеют много преимуществ по сравнению со стандартными БД. Использование символических имен помогает избежать любых изменений адресов тегов при добавлении новых переменных в ваш блок.
С оптимизированными блоками не теряется ни одна область памяти. В отличие от того, что происходит при использовании стандартных БД.
Recommended Comments
There are no comments to display.
Create an account or sign in to comment
You need to be a member in order to leave a comment
Create an account
Sign up for a new account in our community. It's easy!
Register a new accountSign in
Already have an account? Sign in here.
Sign In Now